mysql索引
mysql索引的作用:
对于一个200万条数据的mysql表
//执行下面的SQL语句:
mysql> SELECT id,FROM_UNIXTIME(time) FROM article WHERE a.title='测试标题'
//查询需要的时间非常恐怖的,如果加上联合查询和其他一些约束条件,数据库会疯狂的消耗内存,并且会影响前端程序的执行。这时给title字段添加一个BTREE索引:
mysql> ALTER TABLE article ADD INDEX index_article_title ON title(200);
//再次执行上述查询语句,其对比非常明显:
mysql语句执行顺序:

sql语句优化:
1. 避免使用子查询;
2. 避免使用like语句;
3. 避免使用HAVING字句,应该用where子句替代:
HAVING字句只有在检索出所有记录之后,才会对结果集进行过滤,这样涉及到排序,统计等操作,如果能通过WHERE字句限制记录的数目,就可以减少开销。用Where子句替换HAVING子句。
在多表联接查询时,on比where更早起作用。系统首先根据各个表之间的联接条件,把多个表合成一个临时表后,再由where进行过滤,然后再计算,计算完后再由having进行过滤;
4. 避免使用Order by语句;
5. 避免使用select *:
使用select *的话会增加解析的时间,另外会把不需要的数据也给查询出来,数据传输也是耗费时间的;
mysql索引优化:
1、选择索引的数据类型
MySQL支持很多数据类型,选择合适的数据类型存储数据对性能有很大的影响。通常来说,可以遵循以下一些指导原则:
(1)越小的数据类型通常更好:越小的数据类型通常在磁盘、内存和CPU缓存中都需要更少的空间,处理起来更快。
(2)简单的数据类型更好:整型数据比起字符,处理开销更小,因为字符串的比较更复杂。在MySQL中,应该用内置的日期和时间数据类型,而不是用字符串来存储时间;以及用整型数据类型存储IP地址。
(3)尽量避免NULL:应该指定列为NOT NULL,除非你想存储NULL。在MySQL中,NULL值会使索引失效。你应该用0、一个特殊的值或者一个空串代替空值。
3、避免在索引列上做如下操作:
◆避免在索引字段上使用<>,!=
◆避免在索引列上使用IS NULL和IS NOT NULL
◆避免在索引列上进行计算,例如:数据类型转换
当数据库遇上以上几种符号时,将不再使用索引,使用全表扫描
mysql索引分类:
主键索引:它 是一种特殊的唯一索引,不允许有空值。
唯一索引:与"普通索引"类似,不同的就是:索引列的值必须唯一,但允许有空值。
普通索引:最基本的索引,没有任何限制。
全文索引:仅可用于 MyISAM 表,针对较大的数据,生成全文索引很耗时好空间。
组合索引:为了更多的提高mysql效率可建立组合索引,遵循”最左前缀“原则。创建复合索引时应该将最常用(频率)作限制条件的列放在最左边,依次递减。组合索引最左字段用in是可以用到索引的,最好explain一下select。
怎么创建mysql索引:
PRIMARY KEY(主键索引) ALTER TABLE `table_name` ADD PRIMARY KEY ( `col` )
UNIQUE(唯一索引) ALTER TABLE `table_name` ADD UNIQUE (`col`)
INDEX(普通索引) ALTER TABLE `table_name` ADD INDEX index_name (`col`)
FULLTEXT(全文索引) ALTER TABLE `table_name` ADD FULLTEXT ( `col` )
组合索引 ALTER TABLE `table_name` ADD INDEX index_name (`col1`, `col2`, `col3` )
什么时候用单列索引?什么使用用组合索引?:
场景1: select * from students where name='张三’and age=18;
这种情况name建立单列索引,age的索引不需要创建。
原因: 因为学校里可能会有重名的人,但比较少。用name就可以比较精准的找到记录,即使有重复的也比较少
场景2: 大学选认课老师,需要创建一个关系对应表,有2个字段,student_id 和 teacher_id,想要查询某个老师和某个学生是否存在师生关系。
一个学生会选几十个老师,一个老师会带几百个学生。
select * from students_teachers where student_id='123’and teacher_id='124';
这个时候使用联合索引最合适,通过索引直接找到对应记录,即key index (student_id,teacher_id)。
原因: 两个列都需要筛选
组合索引的通俗解释:
组合索引的结构与电话簿类似,人名由姓和名构成,电话簿首先按姓氏对进行排序,然后按名字对有相同姓氏的人进行排序。如果您知 道姓,电话簿将非常有用;如果您知道姓和名,电话簿则更为有用,但如果您只知道名不姓,电话簿将没有用处。
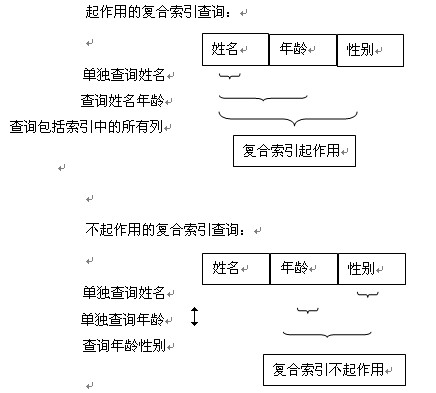
mysql聚簇索引和非聚簇索引:
叶子节点的数据域存放的并不是实际的数据记录,而是数据记录的地址。索引文件与数据文件分离,这样的索引称为“非聚簇索引”
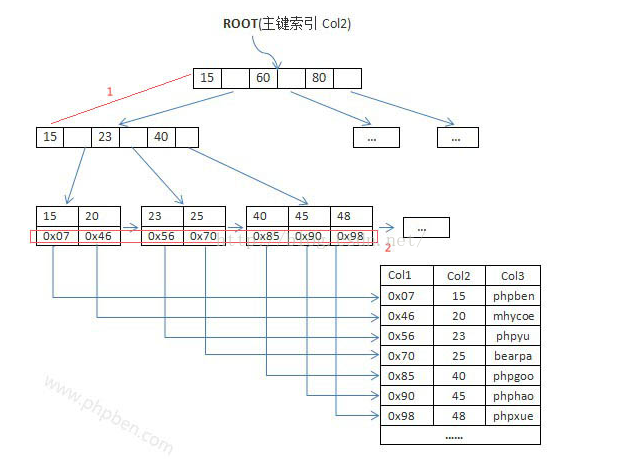
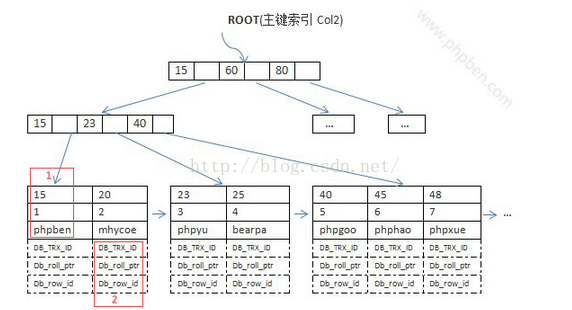
叶子节点的数据域存放的是实际的数据记录(对于主索引,此处会存放表中所有的数据记录;对于辅助索引此处会引用主键,检索的时候通过主键到主键索引中找到对应数据行),这样的索引被称为“聚簇索引”
多表关联时使用索引:

上图可以看出,如果连接字段不加索引,会进行全表扫描;也就是6_6_6,共遍历查询了216次;如果连接字段加索引,那么除第一张表示全表索引(必须的,要以此关联其他表),其余的为range(索引区间获得),也就是6+1+1+1,共遍历查询9次即可;
所以我们建议在多表join的时候尽量少join几张表,另外,我们还建议尽量使用left join,以少关联多.因为使用join 的话,第一张表是必须的全扫描的,以少关联多就可以减少这个扫描次数。
btree索引和hash索引的区别:
(1)Hash索引仅仅能满足"=","IN"和"<=>"查询,不能使用范围查询。
由于 Hash索引比较的是进行Hash运算之后的Hash值,所以它只能用于等值的过滤,不能用于基于范围的过滤,因为经过相应的Hash算法处理之后的Hash值的大小关系,并不能保证和Hash运算前完全一样。
(2)Hash索引无法被用来避免数据的排序操作。
由于Hash索引中存放的是经过Hash计算之后的Hash值,而且Hash值的大小关系并不一定和Hash运算前的键值完全一样,所以数据库无法利用索引的数据来避免任何排序运算。
(3)Hash索引不能利用部分索引键查询。
(4)Hash索引遇到大量Hash值相等的情况后性能并不一定就会比B-Tree索引高。
对于选择性比较低的索引键,如果创建Hash索引,那么将会有大量记录,它们的Hash值相同。这样要定位某一条记录时需要遍历链表,而造成整体性能低下。
索引的弊端:
不要盲目的创建索引,创建索引会降低增加、删除、更新操作的速度,因为执行这些操作的同时会对索引文件进行重新排序或更新;