redis内存结构使用优化
redis内存优化技巧
1. 内存消耗在哪里?
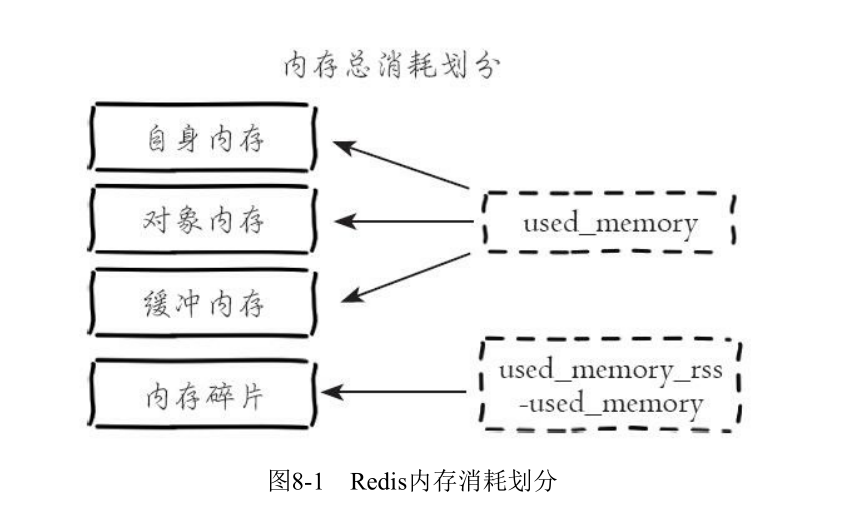
这里我们需要注意的是缓冲内存,缓冲内存包括redis server的输入输出缓冲,所以需要避免对大键值对的查询,以免坑了自己,这跟数据库要分页查询的道理是一样的。一般我们都会设置redis server的maxmemory参数,内存终将用尽,OOM终将发生,有信仰的我们是不会用删除键这种内存溢出策略的,所以如果你的热点数据很多,可以参考我的下一篇博文:redis cluster test
2. 怎样利用现用的内存?
虽然内存是有限的,但对付日常的场景,这几个G还是很好用的。下面是我的一些使用总结:
1. 尽量使用更小的key和value
2. 使用命名空间前缀,规范key的业务范围
3. 如果你要存储对象,请遵循规范:使用专门的VO来存储,不要使用本来有其他用途的Bean
4. 使用正确的redis数据结构缓存数据
5. 根据的业务特点来设置缓存失效时间
6. 当存储字符串时,将字符串的长度限制在39字节内
7. 使用更加高效的序列化反序列化方式,甚至在必要的场景下,压缩数据
8. 水平扩展是为了分散数据,支持更大的数据量,这需要我们去获取和存储数据的时候,尽量使用同一个节点(利用hashTag):将你要缓存的数据按照业务区分,将redis的内存比作一个圆,每一部分数据就是一个扇形,例如档案缓存/登录缓存/权限缓存--->每个加工厂的档案缓存/移动端登录缓存/PC端登录缓存/每个用户的权限缓存,数据量越大,越需要将数据分散。
9. 应该提前预知可能出现缓存雪崩的业务,并为这些keys设置随机的失效时间,或采取其它策略避免。
10. 应该提前预知可能出现缓存击穿(缓存中没有,数据库中有,某一热点数据缓存过期的瞬间,大量请求同时透过缓存,访问到数据库。)的业务,可采用的方式有:
1.可以使热点数据用不过期;
2.互斥锁(使用key值加锁要优于对过程加锁);并避免大量的线程来重建缓存,限制只有一个线程更新缓存;
11. 应该提前预知可能出现缓存穿透(缓存中没有,数据库也没有。)的业务,可采用的方式有:
1.可以对缓存空对象;
2.使用布隆过滤器,将数据库中一定不存在的对象过滤掉;