面试官逼问系列之:HashMap
本章彻底弄懂面试官逼问的HashMap
逼问1:什么是hash表?
hash表:通过一个哈希函数h(key),将关键字key映射为内存单元的某个地址h(key),并将value存储在这个内存单元中,哈希表也称散列表。
逼问2:Map接口都定义了什么方法?
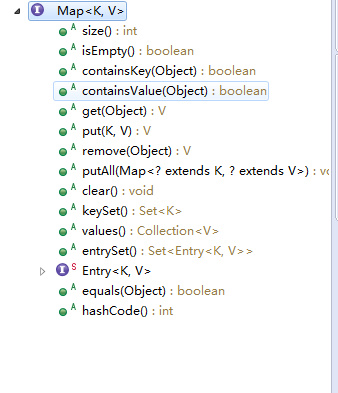
逼问3:介绍下HashMap的存储结构?
一种链表组成的数组结构,为什么是链表呢?我们都知道哈希表解决哈希冲突的方法有开放地址法和链表法,HashMap使用的是链表法。当新建一个HashMap的时候,就会初始化一个Entry数组。
//哈希表数组
transient Entry<K,V>[] table;
...
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
final int hash;
...
}
可以看出,Entry就是数组中的元素,每个 Map.Entry 其实就是一个key-value对,它持有一个指向下一个元素的引用,这就构成了链表。
打开HashMap的源码,映入眼帘的是这段代码:
//数组默认初始容量,总是2的n次方
static final int DEFAULT_INITIAL_CAPACITY = 16;
//数组最大容量,总是2的n次方
static final int MAXIMUM_CAPACITY = 1 << 30;
//默认装填因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//哈希表数组
transient Entry<K,V>[] table;
//哈希表长度
transient int size;
//扩容阀值
int threshold;
//装填因子
final float loadFactor;
//哈希表修改次数,对哈希表数组元素的增删都会使modCount+1
transient int modCount;
逼问4:数组的容量为什么总是2的n次方?
其实解释起来也简单,我们知道哈希表插入数据时需要根据哈希函数得到插入数据的下标,这其中就会有哈希冲突等问题出现。虽然我们能够解决哈希冲突,但是作为HashMap的开发者,肯定是要尽量避免哈希冲突的,怎么避免呢?就是使得哈希函数得到的下标在数组种尽量均匀分布。
atic final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
HashMap的开发者就是使用哈希函数:(h = key.hashCode()) ^ (h >>> 16),使返回的数组下标均匀,例如key的hashcode=766132,转换二进制就是10111011000010110100,
用h >>> 16取出高16位:0000 0000 0000 0000 0000 0000 0000 1011,
则(h = key.hashCode()) ^ (h >>> 16)的运算结果:0000 0000 0000 1011 1011 0000 1011 1111,即十进制766143,使得到的下标均匀分布。
0000 0000 0000 1011 1011 0000 1011 0100
0000 0000 0000 0000 0000 0000 0000 1011 (h >>> 16)
0000 0000 0000 1011 1011 0000 1011 1111 (&)
在JDK1.7中,hash函数长下面这样子:
static int indexFor(int h, int length) {
return h & (length-1);
}
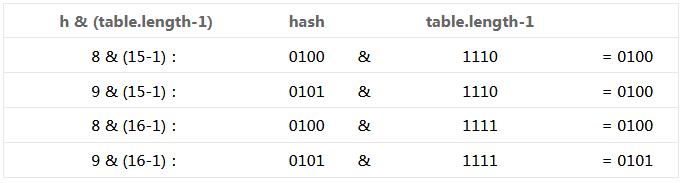
当length总是 2 的n次方时,h & (length-1)运算等价于对length取模,也就是h%length,但是&比%具有更高的效率。设数组长度分别为15和16,优化后的hash码分别为8和9,那么& 运算后的结果如下:
逼问5:说说HashMap的存是怎么实现的?
public V put(K key, V value) {
// HashMap允许存放null键和null值。
// 当key为null时,调用putForNullKey方法,将value放置在数组第一个位置。
if (key == null)
return putForNullKey(value);
// 根据key的keyCode重新计算hash值。
int hash = hash(key.hashCode());
// 搜索指定hash值在对应table中的索引。
int i = indexFor(hash, table.length);
// 如果i索引处的Entry不为null,通过循环不断遍历e元素的下一个元素。
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
// 将key、value添加到i索引处。
addEntry(hash, key, value, i);
return null;
}
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
// 扩容
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
// 根据hash获取Entry位置
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
...
void createEntry(int hash, K key, V value, int bucketIndex) {
// 获取指定bucketIndex索引处的Entry
Entry<K,V> e = table[bucketIndex];
// 将新创建的Entry放入bucketIndex索引处,并让新的Entry指向原来的Entry
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
逼问6:HashMap为什么将头插法改为尾插法?
当我们将一个key-value对放入HashMap中时,先根据key的hashCode计算hash值,根据hash值得到这个元素所在Entry链表在数组中的下标, 如果这个位置上没有元素,就新建一个Entry,在这个位置上的元素将以链表的形式存放。如果有元素,就取出Entry链表,新加入的放在链头,这叫头部插入。但是,在java8之后,都是所用尾部插入了。为啥改为尾部插入呢?这是因为如果使用头部插入,在Hash扩容时会出现环形链表,假设还没扩容前链表是这样的:
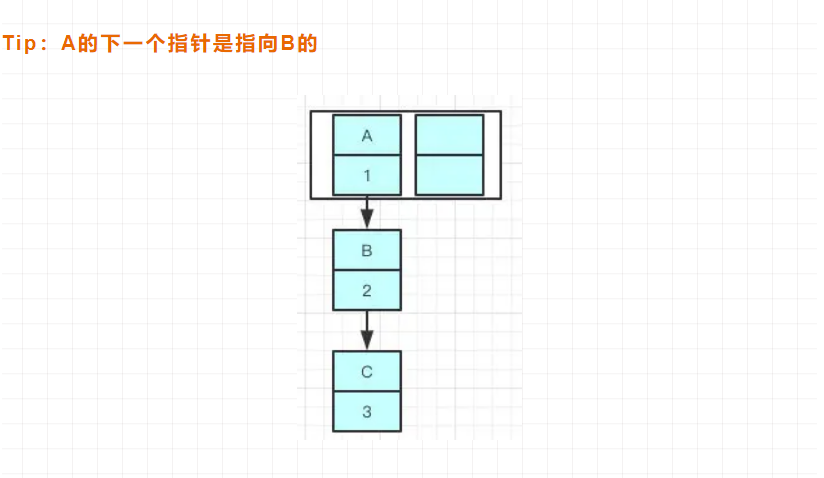
当进行Hash扩容时,A,B,C三个元素通过重新计算索引位置后,有可能被放到了新数组的不同位置上,且使用头部插入,同一位置上新元素总会被放在链表的头部位置,这导致了B被放到了A的前面:
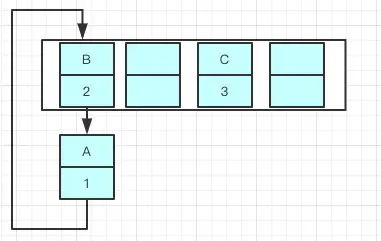
于是A与B成为了环形链表,如果这个时候去取值,悲剧就出现了——Infinite Loop。
但是如果使用尾插,在扩容时会保持链表元素原本的顺序,就不会出现链表成环的问题了。
就是说原本是A->B,在扩容后那个链表还是A->B。
HashMap的取实现
public V get(Object key) {
if (key == null)
return getForNullKey();
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
}
...
private V getForNullKey() {
// 空值是放在数组第一个位置的
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
return null;
}
...
final Entry<K,V> getEntry(Object key) {
int hash = (key == null) ? 0 : hash(key);
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
查找方式为key-->hash-->Entry链表位置-->遍历Entry链表找到key和hash相等的元素。
逼问7:HashMap为什么是线程不安全的?
通过HashMap源码看到put/get方法都没有加同步锁,多线程情况最容易出现的就是:无法保证上一秒put的值,下一秒get的时候还是原值,所以线程安全还是无法保证。