神奇的大作业:HTML转PDF的java项目
PDF格式是一种非常流行的文档格式,在简历/电子图书/参考文档等应用都十分广泛。笔者所在的公司最近也有一个项目,需要将html的图文报告转为PDF格式输出。笔者费了一番功夫,在Github上找到了谷歌的一个开源项目,阅读源码后发现孺子可教,经过修改后的源码完全能达到令产品满意的转换效果。今天咱们就来分享下这个项目。
Definition
- 词法
-
词汇通常用正则表达式表示
INTEGER :0|[1-9][0-9]*
PLUS : +
MINUS: - - 语法
-
语法通常使用一种称为 BNF 的格式来定义
expression := term operation term
operation := PLUS | MINUS
term := INTEGER | expression - iText
-
iText是一个操作PDF文档的开源项目,由java和.net编写。
iText在能够创建标准PDF的同时,还能将XML、HTML、Web表单、CSS或者其他数据库文件转换成PDF,而且保证格式的标准统一。
iText可以切割、合并文档,还对页面进行复制、导入和覆盖的操作,同时可以加入、编写结构更加丰富的多样化内容,比如条形码、水印、印章、表格和图片等。
浏览器解析HTML过程
 作为超文本标记语言,HTML定义了展示网页信息一种规范。浏览器在解释HTML生成最终视图的时候,大概是这样的:
作为超文本标记语言,HTML定义了展示网页信息一种规范。浏览器在解释HTML生成最终视图的时候,大概是这样的:
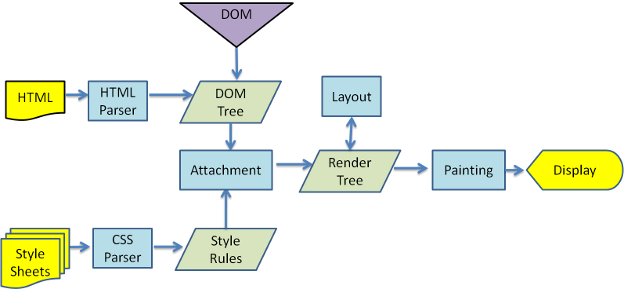
1. 解析文档;
2. 布局,为每个节点分配一个应出现在屏幕上的确切坐标;
3. 绘制,呈现引擎会遍历呈现树,由用户界面后端层将每个节点绘制出来;
4. 显示,值得注意的是这一步并不会等到文档解析完成,会将部分已解析的文档尽快显示。
图1:浏览器主要组件
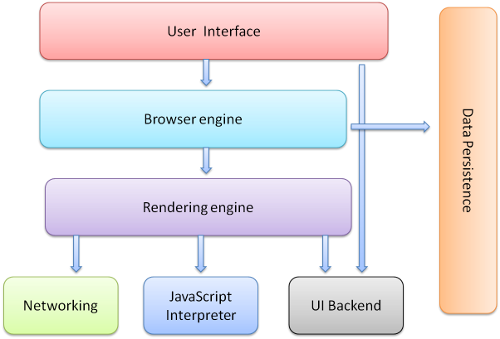
图2:呈现引擎的基本流程

图3:WebKit 主流程
//假设一个HTML文档如下
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="content-type" content="text/html;charset=utf-8" />
</head>
<body>
<!-- 诗词展示 -->
<div style="font-family: msyh;text-align: center;">
<h2>早发白帝城</h2>
<div style="padding: 20px 20px; background-color: rgb(250, 192, 143);font-family: simkai;">
朝辞白帝彩云间,千里江陵一日还。<br />
两岸猿声啼不住,轻舟已过万重山。<br />
</div>
<h2>赠汪伦</h2>
<div style="padding: 20px 20px; background-color: rgb(250, 192, 143);font-family: simkai;">
李白乘舟将欲行,忽闻岸上踏歌声。<br />
桃花潭水深千尺,不及汪伦送我情。<br />
</div>
<h2>望庐山瀑布</h2>
<div style="padding: 20px 20px; background-color: rgb(250, 192, 143);font-family: simkai;">
日照香炉生紫烟,遥看瀑布挂前川。<br />
飞流直下三千尺,疑是银河落九天。<br />
</div>
</div>
<!-- 古词释义 -->
<div style="text-shadow: 5px 5px 5px #787878;color: #fff;background-color: #CDC9C9;">
<p><span style="margin-right: 10px;">☆</span>发:启程。白帝城:故址在今重庆市奉节县白帝山上。</p>
<p><span style="margin-right: 10px;">☆</span>踏歌:唐代民间流行的一种手拉手、两足踏地为节拍的歌舞形式,可以边走边唱。</p>
<p><span style="margin-right: 10px;">☆</span>桃花潭:在今安徽泾县西南一百里。《一统志》谓其深不可测。深千尺:诗人用潭水深千尺比喻汪伦与他的友情,运用了夸张的手法。</p>
</div>
</body>
</html>
 需要解析这个文档,我们需要知道:文档中每个符号代表的意义不是固定的,而是配合当前文档上下文的语义来解释。这意味着,读取同样的字符,可能因为当前状态的不同,得到不同的下一个状态。
需要解析这个文档,我们需要知道:文档中每个符号代表的意义不是固定的,而是配合当前文档上下文的语义来解释。这意味着,读取同样的字符,可能因为当前状态的不同,得到不同的下一个状态。
那么我们可以用数学的方式来解这道难题:
将解析HTML过程中当前状态抽象为“状态”,所有解析操作放在当前“状态”下执行。大概是这样的:
逐个读取文档字符,根据当前状态和读取到字符,进入对应“状态”解析,并触发HTML文档生命周期事件。
首先我们先抽象出HTML文档的生命周期:
/**
* 表示解析HTML文档的生命周期
*
* @author 玄葬
*
*/
public interface HTMLLifeCycle {
public HTMLLifeCycle addHTMLLifeCycleListenter(HTMLLifeCycleListener l);
public HTMLLifeCycle removeHTMLLifeCycleListenter(HTMLLifeCycleListener l);
/**
* 当在开始标签前读取到任何内容时触发
*/
public void unknownText();
/**
* 当读取到开始标签时触发
*/
public void startElement();
/**
* 当读取到结束标签时触发
*/
public void endElement();
/**
* 当读取到注释时触发
*/
public void comment();
}
然后我们抽象出HTML文档的生命周期事件:
/**
* 观察者设计模式
* 监听{@link HTMLLifeCycle}的生命周期
*
* @author 玄葬
*
*/
public interface HTMLLifeCycleListener {
/**
* 标签开始----->pipeline open方法----->生成PDF
*/
void startElement(String tag, Map attributes, String ns);
/**
* 标签结束----->pipeline close方法----->生成PDF
*/
void endElement(String tag, String ns);
/**
* 标签内容----->pipeline content方法----->生成PDF
*/
void text(String text);
/**
* 标签外内容
*/
void unknownText(String text);
/**
* 注释
*/
void comment(String comment);
/**
* 解析开始
*/
void init();
/**
* 解析结束
*/
void close();
}
接下来我们就可以具体实现对HTML文档的解析了,如下面的解析类,实现了HTMLLifeCycle接口,里面的parse方法是解析入口:
/**
* HTML符号识别算法
* 每次读取一个输入字符,并根据这些字符转移到下一个状态,当前的符号状态和当前Dom树状态共同影响结果。
* 这意味着,读取同样的字符,可能因为当前状态的不同,得到不同的下一个状态。
*
* @param r
* @throws IOException
*/
public void parse(final Reader r) throws IOException {
for (HTMLLifeCycleListener l : listeners) {
l.init();
}
char read[] = new char[1];
try {
while (-1 != (r.read(read))) {
state.process(read[0]);
}
} finally {
for (HTMLLifeCycleListener l : listeners) {
l.close();
}
r.close();
}
}
在上面的代码中,state为HTML文档的当前状态,例如读取到标签开始字符“<”,会进入下面这个状态,TagEncounteredState状态下是这样解析字符的:
public class TagEncounteredState implements State {
private final HTMLParser parser;
/**
* @param parser the HTMLParser
*/
public TagEncounteredState(final HTMLParser parser) {
this.parser = parser;
}
@Override
public void process(final char character) {
String tag = this.parser.memory().textBuffString();
if (Character.isWhitespace(character) || character == '>' || character == '/' || character == ':' || character == '?' || tag.equals("!--")) {
if (tag.length() > 0) {
if (tag.equals("!DOCTYPE")) { //<!DOCTYPE html>
this.parser.memory().resetTextBuffer();
this.parser.memory().append(character);
this.parser.stateController().doctype();
}
else if (tag.equals("!--")) { //<!-- this is a comment -->
this.parser.memory().resetTextBuffer();
this.parser.memory().resetCommentBuff();
this.parser.stateController().comment();
/**
* 避免'<!---->'这样的注释出错
* 详见CommentState和CloseCommentState
*/
if (character == '-') {
this.parser.memory().commentBuff().append(character);
} else {
this.parser.memory().append(character);
}
}
else if (Character.isWhitespace(character)) { //<p style="font-size: 14px;">
this.parser.memory().setCurrentTag(tag);
this.parser.memory().resetTextBuffer();
this.parser.stateController().tagAttributes();
}
else if (character == '>') {
this.parser.memory().setCurrentTag(tag);
this.parser.memory().resetTextBuffer();
this.parser.startElement();
this.parser.stateController().inTag();
}
else if (character == '/') {
this.parser.memory().setCurrentTag(tag);
this.parser.memory().resetTextBuffer();
this.parser.stateController().selfClosing();
}
else if (character == ':') {
this.parser.memory().setCurrentNameSpace(tag);
this.parser.memory().resetTextBuffer();
}
} else {
if (character == '/') { //</div
this.parser.stateController().closingTag();
}
else if (character == '?') { //<? xml
this.parser.memory().append(character);
this.parser.stateController().processingInstructions();
}
}
} else {
this.parser.memory().append(character); //<div
}
}
}
TagEncounteredState状态中,当读取到“>”字符时,触发了HTMLLifeCycle的startElement事件,并由HTMLLifeCycleListener监听事件。对于HTMLLifeCycle的每个事件,我们基于观察者设计设计模式观察并处理,例如text事件为写入内容:
@Override
public void text(String text) {
if (text.startsWith("")) {
return;
}
if (null != this.tag) {
Pipeline p = rootpPipe;
ProcessObject po = new ProcessObject();
try {
while((p = p.content(context, this.tag, text, po)) != null);
} catch (PipelineException e) {
throw new RuntimeWorkerException(e);
}
}
}
我们在HTML的startElement、endElement、text事件中接收事件参数,然后进行翻译,具体实现可以参考以下代码:
@Override
public void startElement(String tag, Map attributes, String ns) {
Tag t = new Tag(tag, attributes, ns);
if (this.tag != null) {
this.tag.addChild(t);
}
this.tag = t;
ProcessObject po = new ProcessObject();
Pipeline p = rootpPipe;
try {
while((p = p.open(context, t, po)) != null);
} catch (PipelineException e) {
throw new RuntimeWorkerException(e);
}
}
@Override
public void endElement(String tag, String ns) {
tag = tag.toLowerCase();
if (this.tag != null && !this.tag.getName().equals(tag)) { //判断标签是否闭合
throw new RuntimeWorkerException(String.format(
LocaleMessages.getInstance().getMessage(LocaleMessages.INVALID_NESTED_TAG), tag, this.tag.getName()));
}
Pipeline p = rootpPipe;
ProcessObject po = new ProcessObject();
try {
while((p = p.close(context, this.tag, po)) != null);
} catch (PipelineException e) {
throw new RuntimeWorkerException(e);
} finally {
if (null != this.tag)
this.tag = this.tag.getParent();
}
}
@Override
public void text(String text) {
if (text.startsWith("")) {
return;
}
if (null != this.tag) {
Pipeline p = rootpPipe;
ProcessObject po = new ProcessObject();
try {
while((p = p.content(context, this.tag, text, po)) != null);
} catch (PipelineException e) {
throw new RuntimeWorkerException(e);
}
}
}
其中rootpPipe为我们的管道开头,写入文本的过程中,我们使用责任链模式来分步骤翻译HTML,大概是这个样子的:
接收解析好的Tag标签,并读取影响该标签的CSS样式。----->将这个标签转换为itext元素,并渲染CSS样式到itext元素。----->将itext元素写入document。
于是有了以下代码:
// Pipelines
PdfWriterPipeline pdfWriterPipeline = new PdfWriterPipeline(doc, writer);
HtmlPipeline htmlPipeline = new HtmlPipeline(hpc, pdfWriterPipeline);
CssResolverPipeline cssResolverPipeline = new CssResolverPipeline(cssResolver, htmlPipeline);
其中CssResolverPipeline接收解析好的Tag标签,并读取影响该标签的CSS样式;HtmlPipeline将标签转换为文档元素,并渲染CSS样式到元素;PdfWriterPipeline将元素写入document。主要的思路大概是这样子的:
//我们定义一个Tag类表示HTML标签
public class Tag implements Iterable {
private Tag parent;
private final String tag;
private final Map attributes;
private Map css;
private final List children;
private final String ns;
private Object lastMarginBottom = null;
/**
* CssResolverPipeline接收Tags标签并渲染CSS样式
*
* @author 玄葬
*
*/
public class CssResolverPipeline extends AbstractPipeline {
private CSSResolver cssResolver;
public CssResolverPipeline(final CSSResolver cssResolver, final Pipeline next) {
super(next);
this.cssResolver = cssResolver;
}
@Override
public String getContextKey() {
return CssResolverPipeline.class.getName();
}
@Override
public Pipeline init(WorkerContext context) throws PipelineException {
try {
CSSResolver ctx = cssResolver.clear(); // 使用CSSResolver上下文之前先清空非持久化CSS文件
context.put(getContextKey(), ctx);
return getNext();
} catch (CssResolverException e) {
throw new PipelineException(e);
}
}
@Override
public Pipeline open(WorkerContext context, Tag t, ProcessObject po) throws PipelineException {
CSSResolver cssResolver = getLocalContext(context);
cssResolver.resolve(t);
return getNext();
}
}
其中CssResolverPipeline读取能影响该标签CSS过程大概是这样子的(支持文本和流的形式读取CSS文件):
@Override
public void resolve(Tag t) {
Map css = t.getCSS(); //标签最终的CSS
Map tagCss = new LinkedHashMap(); //从CSS样式表和标签style属性获取的CSS
// 解析CSS文件
if (null != cssFiles && cssFiles.hasFiles()) {
tagCss = cssFiles.getCSS(t);
if (t.getName().equalsIgnoreCase(HTML.Tag.P) || t.getName().equalsIgnoreCase(HTML.Tag.TD)) {
Map listCss = cssFiles.getCSS(new Tag(HTML.Tag.UL));
if (listCss.containsKey(CSS.Property.LIST_STYLE_TYPE)) { // list-style-type的样式
css.put(CSS.Property.LIST_STYLE_TYPE, listCss.get(CSS.Property.LIST_STYLE_TYPE));
}
}
}
// 解析style属性
Map attributes = t.getAttributes();
if (null != attributes && !attributes.isEmpty()) {
if (attributes.get(HTML.Attribute.CELLPADDING) != null) {
tagCss.putAll(utils.parseBoxValues(attributes.get(HTML.Attribute.CELLPADDING), "cellpadding-", ""));
}
if (attributes.get(HTML.Attribute.CELLSPACING) != null) {
tagCss.putAll(utils.parseBoxValues(attributes.get(HTML.Attribute.CELLSPACING), "cellspacing-", ""));
}
String style = attributes.get(HTML.Attribute.STYLE);
if (null != style && style.length() > 0) {
Map styleCss = new LinkedHashMap();
String[] styles = style.split(";");
for (String s : styles) {
String[] part = s.split(":", 2);
if (part.length == 2) {
String key = utils.stripDoubleSpacesTrimAndToLowerCase(part[0]);
String value = utils.stripDoubleSpacesAndTrim(part[1]);
parseAttributeValue(styleCss, key, value);
}
}
tagCss.putAll(styleCss);
}
}
// 特殊标签处理
if (t.getName() != null) {
if(t.getName().equalsIgnoreCase(HTML.Tag.I) || t.getName().equalsIgnoreCase(HTML.Tag.CITE)
|| t.getName().equalsIgnoreCase(HTML.Tag.EM) || t.getName().equalsIgnoreCase(HTML.Tag.VAR)
|| t.getName().equalsIgnoreCase(HTML.Tag.DFN) || t.getName().equalsIgnoreCase(HTML.Tag.ADDRESS)) {
tagCss.put(CSS.Property.FONT_STYLE, CSS.Value.ITALIC);
}
else if (t.getName().equalsIgnoreCase(HTML.Tag.B) || t.getName().equalsIgnoreCase(HTML.Tag.STRONG)) {
tagCss.put(CSS.Property.FONT_WEIGHT, CSS.Value.BOLD);
}
else if (t.getName().equalsIgnoreCase(HTML.Tag.U) || t.getName().equalsIgnoreCase(HTML.Tag.INS)) {
tagCss.put(CSS.Property.TEXT_DECORATION, CSS.Value.UNDERLINE);
}
else if (t.getName().equalsIgnoreCase(HTML.Tag.S) || t.getName().equalsIgnoreCase(HTML.Tag.STRIKE)
|| t.getName().equalsIgnoreCase(HTML.Tag.DEL)) {
tagCss.put(CSS.Property.TEXT_DECORATION, CSS.Value.LINE_THROUGH);
}
else if (t.getName().equalsIgnoreCase(HTML.Tag.BIG)){
tagCss.put(CSS.Property.FONT_SIZE, CSS.Value.LARGER);
}
else if (t.getName().equalsIgnoreCase(HTML.Tag.SMALL)){
tagCss.put(CSS.Property.FONT_SIZE, CSS.Value.SMALLER);
}
else if (t.getName().equals(HTML.Tag.FONT)) {
String font_family = t.getAttributes().get(HTML.Attribute.FACE);
if (font_family != null) css.put(CSS.Property.FONT_FAMILY, font_family);
String color = t.getAttributes().get(HTML.Attribute.COLOR);
if (color != null) css.put(CSS.Property.COLOR, color);
String size = t.getAttributes().get(HTML.Attribute.SIZE);
if (size != null) {
if(size.equals("1")) css.put(CSS.Property.FONT_SIZE, CSS.Value.XX_SMALL);
else if(size.equals("2")) css.put(CSS.Property.FONT_SIZE, CSS.Value.X_SMALL);
else if(size.equals("3")) css.put(CSS.Property.FONT_SIZE, CSS.Value.SMALL);
else if(size.equals("4")) css.put(CSS.Property.FONT_SIZE, CSS.Value.MEDIUM);
else if(size.equals("5")) css.put(CSS.Property.FONT_SIZE, CSS.Value.LARGE);
else if(size.equals("6")) css.put(CSS.Property.FONT_SIZE, CSS.Value.X_LARGE);
else if(size.equals("7")) css.put(CSS.Property.FONT_SIZE, CSS.Value.XX_LARGE);
}
}
else if (t.getName().equals(HTML.Tag.A)) {
css.put(CSS.Property.TEXT_DECORATION, CSS.Value.UNDERLINE);
css.put(CSS.Property.COLOR, "blue");
}
}
// 解析父类可继承属性
if (null != t.getParent() && null != t.getParent().getCSS()) {
Map parentCss = t.getParent().getCSS();
for (Entry pc : parentCss.entrySet()) {
String key = pc.getKey();
String value = pc.getValue();
if ((tagCss.containsKey(key) && CSS.Value.INHERIT.equalsIgnoreCase(tagCss.get(key))) || (!tagCss.containsKey(key) && canInherite(t, key))) {
if (key.contains(CSS.Property.CELLPADDING) && (HTML.Tag.TD.equals(t.getName()) || HTML.Tag.TH.equals(t.getName()))) {
String paddingKey = key.replace(CSS.Property.CELLPADDING, CSS.Property.PADDING); // 将TD和TH元素cellpadding属性转为padding,PDF元素转换只支持padding属性?
tagCss.put(paddingKey, value);
}else{
css.put(key, value);
}
}
}
}
// 加到最终CSS,如果value!=inherit则覆盖
for (Entry kv : tagCss.entrySet()) {
if (!kv.getValue().equalsIgnoreCase(CSS.Value.INHERIT)) {
if (kv.getKey().equals(CSS.Property.TEXT_DECORATION)) {
String oldValue = css.get(kv.getKey());
css.put(kv.getKey(), mergeTextDecorationRules(oldValue, kv.getValue()));
}else{
css.put(kv.getKey(), kv.getValue());
}
}
}
}
/**
* HtmlPipeline将标签和文本转换为PDF Elements
*
* @author 玄葬
*
*/
public class HtmlPipeline extends AbstractPipeline {
private final HtmlPipelineContext hpc;
public HtmlPipeline(final HtmlPipelineContext hpc, final Pipeline next) {
super(next);
this.hpc = hpc;
}
@Override
public String getContextKey() {
return HtmlPipeline.class.getName();
}
@Override
public Pipeline init(final WorkerContext context) throws PipelineException {
context.put(getContextKey(), hpc);
return getNext();
}
@Override
public Pipeline open(final WorkerContext context, final Tag t, final ProcessObject po) throws PipelineException {
HtmlPipelineContext hcc = getLocalContext(context);
try {
t.setLastMarginBottom(hcc.getMemory().get(HtmlPipelineContext.LAST_MARGIN_BOTTOM));
hcc.getMemory().remove(HtmlPipelineContext.LAST_MARGIN_BOTTOM);
TagProcessor tp = hcc.getProcessor(t.getName(), t.getNameSpace());
addStackKeeper(t, hcc, tp);
List content = tp.startElement(context, t);
if (content.size() > 0) {
if (tp.isStackOwner()) {
StackKeeper peek = hcc.peek();
if (peek == null)
throw new PipelineException(String.format(LocaleMessages.STACK_404, t.toString()));
for (Element elem : content) {
peek.add(elem);
}
} else {
for (Element elem : content) {
hcc.getElements().add(elem);
if (elem.type() == Element.BODY ){
WritableElement writableElement = new WritableElement();
writableElement.add(elem);
po.add(writableElement);
hcc.getElements().remove(elem);
}
}
}
}
} catch (NoTagProcessorException e) {
if (!hcc.acceptUnknown()) {
throw e;
}
}
return getNext();
}
@Override
public Pipeline content(final WorkerContext context, final Tag t, final String text, final ProcessObject po)
throws PipelineException {
HtmlPipelineContext hcc = getLocalContext(context);
TagProcessor tp;
try {
tp = hcc.getProcessor(t.getName(), t.getNameSpace());
// String ctn = null;
// if (null != hcc.charSet()) {
// try {
// ctn = new String(b, hcc.charSet().name());
// } catch (UnsupportedEncodingException e) {
// throw new RuntimeWorkerException(LocaleMessages.getInstance().getMessage(
// LocaleMessages.UNSUPPORTED_CHARSET), e);
// }
// } else {
// ctn = new String(b);
// }
List elems = tp.content(context, t, text);
if (elems.size() > 0) {
StackKeeper peek = hcc.peek();
if (peek != null) {
for (Element e : elems) {
peek.add(e);
}
} else {
WritableElement writableElement = new WritableElement();
for (Element elem : elems) {
writableElement.add(elem);
}
po.add(writableElement);
}
}
} catch (NoTagProcessorException e) {
if (!hcc.acceptUnknown()) {
throw e;
}
}
return getNext();
}
@Override
public Pipeline close(final WorkerContext context, final Tag t, final ProcessObject po) throws PipelineException {
HtmlPipelineContext hcc = getLocalContext(context);
TagProcessor tp;
try {
if (t.getLastMarginBottom() != null) {
hcc.getMemory().put(HtmlPipelineContext.LAST_MARGIN_BOTTOM, t.getLastMarginBottom());
} else {
hcc.getMemory().remove(HtmlPipelineContext.LAST_MARGIN_BOTTOM);
}
tp = hcc.getProcessor(t.getName(), t.getNameSpace());
List elems = null;
if (tp.isStackOwner()) {
// remove the element from the StackKeeper Queue if end tag is
// found
StackKeeper tagStack;
try {
tagStack = hcc.poll();
} catch (NoStackException e) {
throw new PipelineException(String.format(
LocaleMessages.getInstance().getMessage(LocaleMessages.STACK_404), t.toString()), e);
}
elems = tp.endElement(context, t, tagStack.getElements());
} else {
elems = tp.endElement(context, t, hcc.getElements());
hcc.getElements().clear();
}
if (elems.size() > 0) {
StackKeeper stack = hcc.peek();
if (stack != null) {
for (Element elem : elems) {
stack.add(elem);
}
} else {
WritableElement writableElement = new WritableElement();
po.add(writableElement);
writableElement.addAll(elems);
}
}
} catch (NoTagProcessorException e) {
if (!hcc.acceptUnknown()) {
throw e;
}
}
return getNext();
}
protected void addStackKeeper(Tag t, HtmlPipelineContext hcc, TagProcessor tp) {
if (tp.isStackOwner()) {
hcc.addFirst(new StackKeeper(t));
}
}
}
/**
* This pipeline writes to a Document.
* @author redlab_b
*
*/
public class PdfWriterPipeline extends AbstractPipeline {
private static final Logger LOG = LoggerFactory.getLogger(PdfWriterPipeline.class);
private Document doc;
private PdfWriter writer;
/**
*/
public PdfWriterPipeline() {
super(null);
}
/**
* @param next the next pipeline if any.
*/
public PdfWriterPipeline(final Pipeline next) {
super(next);
}
/**
* @param doc the document
* @param writer the writer
*/
public PdfWriterPipeline(final Document doc, final PdfWriter writer) {
super(null);
this.doc = doc;
this.writer = writer;
continiously = true;
}
/**
* The key for the {@link Document} in the {@link MapContext} used as {@link CustomContext}.
*/
public static final String DOCUMENT = "DOCUMENT";
/**
* The key for the {@link PdfWriter} in the {@link MapContext} used as {@link CustomContext}.
*/
public static final String WRITER = "WRITER";
/**
* The key for the a boolean in the {@link MapContext} used as {@link CustomContext}. Setting to true enables swallowing of DocumentExceptions
*/
public static final String CONTINUOUS = "CONTINUOUS";
private Boolean continiously;
/* (non-Javadoc)
* @see com.itextpdf.tool.xml.pipeline.AbstractPipeline#init(com.itextpdf.tool.xml.WorkerContext)
*/
@Override
public Pipeline init(final WorkerContext context) throws PipelineException {
MapContext mc = new MapContext();
continiously = Boolean.TRUE;
mc.put(CONTINUOUS, continiously);
if (null != doc) {
mc.put(DOCUMENT, doc);
}
if (null != writer) {
mc.put(WRITER, writer);
}
context.put(getContextKey(), mc);
return super.init(context);
}
/**
* @param po
* @throws PipelineException
*/
private void write(final WorkerContext context, final ProcessObject po) throws PipelineException {
MapContext mp = getLocalContext(context);
if (po.containsWritable()) {
Document doc = (Document) mp.get(DOCUMENT);
boolean continuousWrite = (Boolean) mp.get(CONTINUOUS);
Writable writable = null;
while (null != (writable = po.poll())) {
if (writable instanceof WritableElement) {
for (Element e : ((WritableElement) writable).elements()) {
try {
if (!doc.add(e)) {
LOG.trace(String.format(
LocaleMessages.getInstance().getMessage(LocaleMessages.ELEMENT_NOT_ADDED),
e.toString()));
}
} catch (DocumentException e1) {
if (!continuousWrite) {
throw new PipelineException(e1);
} else {
LOG.error(
LocaleMessages.getInstance().getMessage(LocaleMessages.ELEMENT_NOT_ADDED_EXC),
e1);
}
}
}
}
}
}
}
/*
* (non-Javadoc)
*
* @see com.itextpdf.tool.xml.pipeline.Pipeline#open(com.itextpdf.tool.
* xml.Tag, com.itextpdf.tool.xml.pipeline.ProcessObject)
*/
@Override
public Pipeline open(final WorkerContext context, final Tag t, final ProcessObject po) throws PipelineException {
write(context, po);
return getNext();
}
/*
* (non-Javadoc)
*
* @see com.itextpdf.tool.xml.pipeline.Pipeline#content(com.itextpdf.tool
* .xml.Tag, java.lang.String, com.itextpdf.tool.xml.pipeline.ProcessObject)
*/
@Override
public Pipeline content(final WorkerContext context, final Tag currentTag, final String text, final ProcessObject po) throws PipelineException {
write(context, po);
return getNext();
}
/*
* (non-Javadoc)
*
* @see com.itextpdf.tool.xml.pipeline.Pipeline#close(com.itextpdf.tool
* .xml.Tag, com.itextpdf.tool.xml.pipeline.ProcessObject)
*/
@Override
public Pipeline close(final WorkerContext context, final Tag t, final ProcessObject po) throws PipelineException {
write(context ,po);
return getNext();
}
/**
* The document to write to.
* @param document the Document
*/
public void setDocument(final Document document) {
this.doc = document;
}
/**
* The writer used to write to the document.
* @param writer the writer.
*/
public void setWriter(final PdfWriter writer) {
this.writer = writer;
}
@Override
public String getContextKey() {
return PdfWriterPipeline.class.getName();
}
}
在标签----->元素的转换过程中,CSS渲染是最具有技术难度的工作,例如将一个<p>标签渲染成Chunk元素
@Override
public List content(final WorkerContext ctx, final Tag tag, final String content) {
List sanitizedChunks = HTMLUtils.sanitize(content, false);
List l = new ArrayList(1);
for (Chunk sanitized : sanitizedChunks) {
try {
HtmlPipelineContext hpc = getHtmlPipelineContext(ctx);
if ((null != tag.getCSS().get(CSS.Property.TAB_INTERVAL))) {
TabbedChunk tabbedChunk = new TabbedChunk(sanitized.getContent());
if (null != getLastChild(tag) && null != getLastChild(tag).getCSS().get(CSS.Property.XFA_TAB_COUNT)) {
tabbedChunk.setTabCount(Integer.parseInt(getLastChild(tag).getCSS().get(CSS.Property.XFA_TAB_COUNT)));
}
l.add(getCssApplyService().apply(tabbedChunk, tag, hpc));
} else if (null != getLastChild(tag) && null != getLastChild(tag).getCSS().get(CSS.Property.XFA_TAB_COUNT)) {
TabbedChunk tabbedChunk = new TabbedChunk(sanitized.getContent());
tabbedChunk.setTabCount(Integer.parseInt(getLastChild(tag).getCSS().get(CSS.Property.XFA_TAB_COUNT)));
l.add(getCssApplyService().apply(tabbedChunk, tag, hpc));
} else {
l.add(getCssApplyService().apply(sanitized, tag, hpc));
}
} catch (NoCustomContextException e) {
throw new RuntimeWorkerException(e);
}
}
return l;
}
getCssApplyService()方法获取CSS渲染接口,该接口提供统一的apply()方法,自动判断需要渲染的元素类型,找到该元素的渲染类用于渲染CSS,例如ParagraphCssApplier类渲染Paragraph元素大概是这样的:
public Paragraph apply(final Paragraph p, final Tag t, final MarginMemory configuration, final PageSizeContainable psc, final HtmlPipelineContext ctx) {
//when turning html p tag to pdf Paragraph, height should be fixed
final CssUtils utils = CssUtils.getInstance();
float fontSize = FontSizeTranslator.getInstance().getFontSize(t);
if (fontSize == Font.UNDEFINED) fontSize = 0;
float lmb = 0;
boolean hasLMB = false;
Map css = t.getCSS();
for (Entry entry : css.entrySet()) {
String key = entry.getKey();
String value = entry.getValue();
if (CSS.Property.MARGIN_TOP.equalsIgnoreCase(key)) {
p.setSpacingBefore(p.getSpacingBefore() + utils.calculateMarginTop(value, fontSize, configuration));
} else if (CSS.Property.PADDING_TOP.equalsIgnoreCase(key)) {
p.setSpacingBefore(p.getSpacingBefore() + utils.parseValueToPt(value, fontSize));
p.setPaddingTop(utils.parseValueToPt(value, fontSize));
} else if (CSS.Property.MARGIN_BOTTOM.equalsIgnoreCase(key)) {
float after = utils.parseValueToPt(value, fontSize);
p.setSpacingAfter(p.getSpacingAfter() + after);
lmb = after;
hasLMB = true;
} else if (CSS.Property.PADDING_BOTTOM.equalsIgnoreCase(key)) {
p.setSpacingAfter(p.getSpacingAfter() + utils.parseValueToPt(value, fontSize));
} else if (CSS.Property.MARGIN_LEFT.equalsIgnoreCase(key)) {
p.setIndentationLeft(p.getIndentationLeft() + utils.parseValueToPt(value, fontSize));
} else if (CSS.Property.MARGIN_RIGHT.equalsIgnoreCase(key)) {
p.setIndentationRight(p.getIndentationRight() + utils.parseValueToPt(value, fontSize));
} else if (CSS.Property.PADDING_LEFT.equalsIgnoreCase(key)) {
p.setIndentationLeft(p.getIndentationLeft() + utils.parseValueToPt(value, fontSize));
} else if (CSS.Property.PADDING_RIGHT.equalsIgnoreCase(key)) {
p.setIndentationRight(p.getIndentationRight() + utils.parseValueToPt(value, fontSize));
} else if (CSS.Property.TEXT_ALIGN.equalsIgnoreCase(key)) {
p.setAlignment(CSS.getElementAlignment(value));
} else if (CSS.Property.TEXT_INDENT.equalsIgnoreCase(key)) {
p.setFirstLineIndent(utils.parseValueToPt(value, fontSize));
} else if (CSS.Property.LINE_HEIGHT.equalsIgnoreCase(key)) {
if(utils.isNumericValue(value)) {
p.setLeading(Float.parseFloat(value) * fontSize);
} else if (utils.isRelativeValue(value)) {
p.setLeading(utils.parseRelativeValue(value, fontSize));
} else if (utils.isMetricValue(value)){
p.setLeading(utils.parsePxInCmMmPcToPt(value));
}
}
}
if ( t.getAttributes().containsKey(HTML.Attribute.ALIGN)) {
String value = t.getAttributes().get(HTML.Attribute.ALIGN);
if ( value != null ) {
p.setAlignment(CSS.getElementAlignment(value));
}
}
// setDefaultMargin to largestFont if no margin-bottom is set and p-tag is child of the root tag.
/*if (null != t.getParent()) {
String parent = t.getParent().getName();
if (css.get(CSS.Property.MARGIN_TOP) == null && configuration.getRootTags().contains(parent)) {
p.setSpacingBefore(p.getSpacingBefore() + utils.calculateMarginTop(fontSize + "pt", 0, configuration));
}
if (css.get(CSS.Property.MARGIN_BOTTOM) == null && configuration.getRootTags().contains(parent)) {
p.setSpacingAfter(p.getSpacingAfter() + fontSize);
css.put(CSS.Property.MARGIN_BOTTOM, fontSize + "pt");
lmb = fontSize;
hasLMB = true;
}
//p.setLeading(m.getLargestLeading()); We need possibility to detect that line-height undefined;
if (p.getAlignment() == -1) {
p.setAlignment(Element.ALIGN_LEFT);
}
}*/
if (hasLMB) {
configuration.setLastMarginBottom(lmb);
}
ChunkCssApplier chunkCssApplier = (ChunkCssApplier) cssApplyService.getCssApplier(Chunk.class);
Font font = chunkCssApplier.applyFontStyles(t);
p.setFont(font);
// TODO reactive for positioning and implement more
// if(null != configuration.getWriter() && null != css.get("position")) {
// positionNoNewLineParagraph(p, css);
// p = null;
// }
return p;
}
剩下的工作就是写入Writable元素集合到document了,详见项目代码:https://github.com/linfengda/htmlworker.git
转换的效果大概是这样子的:

使用楷体转换的效果大概是这样子的:

实际项目中的效果:
